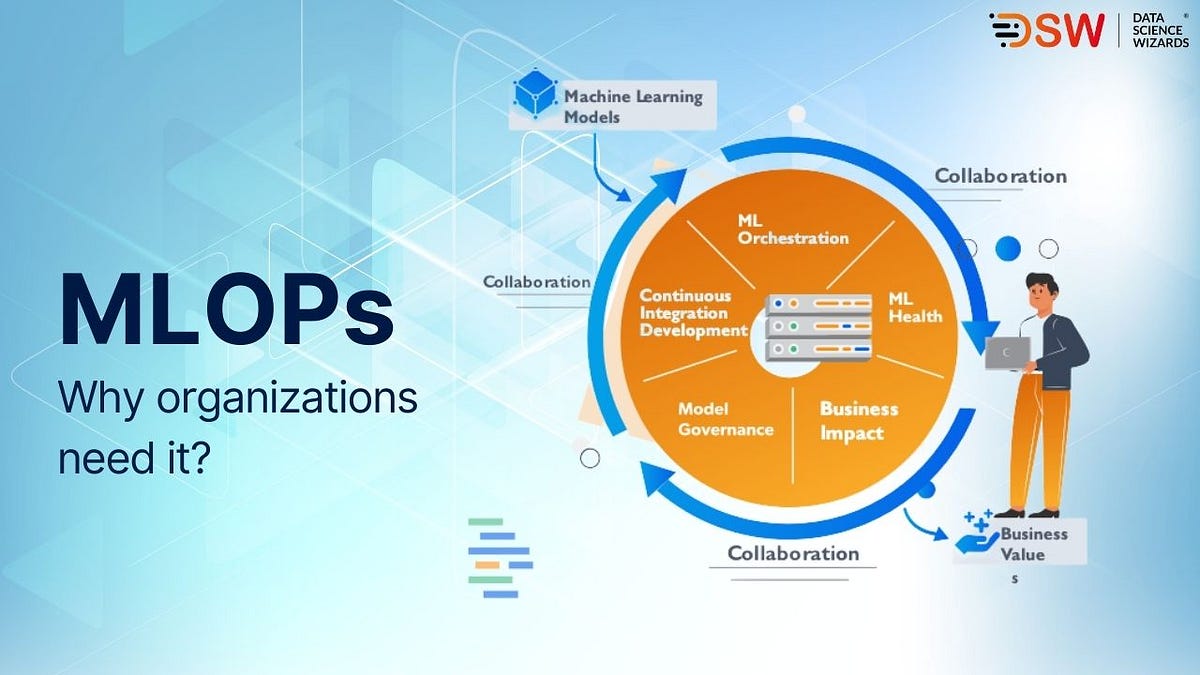

Machine Learning Operations, or MLOps for short, is a field that streamlines the creation, deployment, and maintenance of machine learning models in production environments by fusing machine learning (ML) with DevOps methods. To guarantee the effective and dependable delivery of ML applications, it focuses on bridging the gap between data science and operations teams.
MLOps’ primary goal is to solve the difficulties involved in implementing and managing machine learning models on a large scale. Processes including data pretreatment, model training, assessment, deployment, monitoring, and maintenance can all be automated in this way. Organisations may increase model performance, boost overall productivity, and shorten the time-to-market for machine learning applications by implementing MLOps principles.
The field of machine learning and operations, or MLOps, has become increasingly important in technology. It provides an organised method for scaling, managing, and implementing machine learning models in real-world settings. The need for qualified professionals knowledgeable in MLOps methods is only going to increase as more and more industries use machine learning to automate processes and make decisions.
Starting an MLOps journey requires figuring out a plethora of ideas, resources, and procedures. Experience in the real world is just as significant as theoretical knowledge. Aspiring MLOps practitioners can learn the subtleties of model construction, deployment, and maintenance through practical projects.
The deployment, scaling, and management of machine learning models in production contexts are the main areas of focus for the quickly developing field of machine learning operations, or MLOps. Several industries have seen a sharp increase in the use of machine learning technology in recent years, which has increased the demand for reliable and effective procedures for operationalizing these models. You must begin your MLOps journey with real tasks to obtain practical experience and comprehend the fundamental ideas involved. We’ll look at eight beginner-friendly projects in this article to help get people started on MLOps in 2021.
- Configuring an Environment for Development:
Setting up a strong development environment is essential before tackling MLOps to create and train machine learning models. Start by deciding which frameworks and technologies are best for your project based on its specifications. Python’s large library and active community make it a popular choice for machine-learning applications. An interactive platform for machine learning algorithm design and experimentation is offered by Jupyter Notebooks. Installing libraries like PyTorch or TensorFlow for deep learning jobs is another thing to think about.
After selecting your tools, make sure your system has them installed and configured correctly. Python libraries and dependencies can be installed using package managers such as pip or conda. To separate your project’s dependencies and prevent problems with other projects, create a virtual environment. Organising a robust development environment will streamline your workflow and make it easier to iterate on your machine-learning projects.
- Using Git for Version Control:
A crucial component of contemporary software development, including machine learning initiatives, is version control. Git is a popular version control system that lets you work with team members, keep track of changes made to your codebase, and go back to earlier iterations when necessary. To begin, commit your basic codebase to a Git repository for your machine learning project.
Use Git to keep track of code modifications while you work on your project and try out various strategies. By using branches, you can work on experiments or new features without impacting the main codebase. After changes are verified and tested, merge them back into the main branch. Work together as a team by transferring and pulling changes between distant repositories like GitHub or GitLab. By mastering Git, you’ll ensure better collaboration and reproducibility in your machine-learning projects.
- Data Preprocessing Pipeline: Cleaning, converting, and preparing data for model training are all part of the critical data preprocessing stage in the machine learning pipeline. Examine your dataset to find any missing or inconsistent values first. Implement strategies like imputation or deletion to efficiently manage missing data. Next, use feature engineering to extract pertinent data and generate new features that highlight significant trends in the data.
Using tools like pandas or sci-kit-learn, create a preprocessing pipeline after the data has been cleaned and engineered. Every preprocessing step should be included in this pipeline, and it should guarantee consistency when doing it on fresh data. Make sure your preparation pipeline generates the appropriate output by testing it on a sample dataset. Gaining proficiency in data preparation will the quality and reliability of the models.
- Model Training and Evaluation –
To reduce the prediction error, a suitable algorithm must be chosen, training data must be fed into it, and its parameters must be optimised. Begin by playing with various machine learning algorithms, such as neural networks, decision trees, and linear regression. Utilising relevant measures like accuracy, precision, recall, and F1-score, train each model on your dataset.
After assessing several models, choose the model that exhibits the best performance using your validation data. To further enhance the model’s performance, adjust its hyperparameters. To make sure the model is resilient and prevent overfitting, think about applying methods like cross-validation. Lastly, test the generalisation capacity of your model using an alternative test dataset. You may create dependable and accurate machine-learning models by becoming an expert in model training and evaluation.
- Model deployment with Docker –
The process of making your trained model available for inference in real-world settings is known as model deployment. With the help of the containerisation platform Docker, you can bundle your model and all of its dependencies into a small, portable container. To begin, create a Dockerfile that lists the setup and dependencies needed to execute your model.
Construct the Docker image and run a local test to make sure everything functions as it should. Deploy the Docker image to an AWS, Azure, or Google Cloud production environment after you’re happy with the outcome. Employ Kubernetes or other container orchestration solutions to effectively manage and grow your deployed models. You will be able to deploy your machine learning models confidently and easily if you understand how to use Docker for model deployment.
- Continuous Integration Pipeline –
Code integration and testing are automated as part of the software development process known as continuous integration, or CI. CI pipelines support maintaining the consistency and quality of your machine learning codebase in the context of machine learning. First, create a continuous integration (CI) server using GitHub Actions, Travis CI, or Jenkins.
Set up your continuous integration pipeline to automatically test your machine learning code each time a new version of the code is submitted to the repository. Unit tests, integration tests, and model assessment metrics are a few examples of these tests. To write and run your tests, use programmes like TensorFlow Extended (TFX) or Pytest. Your machine learning codebase will stay dependable and manageable for the duration of its lifecycle if you can effectively manage continuous integration workflows.

- Model Monitoring and Logging –
It is crucial to keep an eye on your model’s performance once it has been put into production and to identify any irregularities or deviations immediately. Configure logging and monitoring tools like Grafana, Prometheus, or the ELK stack to keep tabs on system health, faults, and model metrics. Keep an eye on important metrics like accuracy, throughput, and prediction latency.
Establish alerts to inform you of any activity that deviates from expectations, and then take prompt action to remedy it. Logging records pertinent data for debugging and auditing purposes regarding model predictions, inputs, and outputs. You can make sure that your deployed machine-learning models are dependable and durable by becoming an expert in model monitoring and logging.
- Model Lifecycle Management –
Machine learning models require a variety of tasks to be managed during their lifecycle, such as versioning, retraining, and re-deployment. Create a versioning mechanism to monitor model modifications and guarantee repeatability. Create automated retraining pipelines to continuously add new data to your models, enhancing their performance over time.
Use strategies like phased rollouts and A/B testing to safely introduce fresh iterations of your models. When deployed models stop meeting the required performance standards or become outdated, retire them and keep an eye on their performance. By becoming an expert in model lifecycle management, You can ensure that your machine learning models are accurate, dependable, and current throughout their lives.
Youtube Video – What is MLOps | MLOps Explained in just 3-minutes | Introduction to MLOps | Intellipaat (youtube.com)
It can be intimidating to start your MLOps adventure, but with the correct projects and direction, you can quickly acquire the abilities and knowledge required for success. You can gain a strong foundation in MLOps and prepare yourself to take on more difficult tasks in the industry by finishing the eight projects listed in this article. As you advance on your MLOps journey, never forget to explore, iterate, and never stop learning. Employing commitment and persistence, it is possible to realise the potential of machine learning in practical applications fully.