

“When radar and vision disagree, which one do you believe? Vision has much more precision, so better to double down on vision than do sensor fusion.”
This was a tweet made by Tesla CEO Elon Musk a long time back in April. Additionally, in his talk at Tesla Autonomy Day (Link to Talk), Elon Musk said:
“LiDAR is a fool’s errand, and anyone relying on LiDAR is doomed. LiDARs are expensive sensors that are unnecessary. It’s like having a whole bunch of expensive appendices. Like, one appendix is bad, well now you have a whole bunch of them, it’s ridiculous, you’ll see.”
Almost every self-driving car company makes use of a LiDAR sensor. Uber, Waymo, and Lyft except for Tesla, all use LiDARs.
But, why Tesla so heavily relies on vision, what makes cameras so powerful and what can we accomplish from them, are all going to be discussed in this blog.
Cameras, LiDARs and RADARs
Self-driving cars and other advanced robot systems make use of several different sensors. These are Cameras, LiDARs, RADARs, IMUs, and GPS.
A camera is an optical instrument that captures a visual image. In simple terms, cameras are boxes with a small hole that allow light through to capture an image on a light-sensitive surface. They allow robots to see and visualize the environment similar to human vision.

LiDAR stands for Light Detection and Ranging. A LiDAR sensor sends out beams of infrared light into its surroundings and by capturing the reflection of those beams creates a point cloud (set of points in space) data. LiDARs help robots to scan their complete surrounding environment. The working of LiDAR is shown on the right. (Credit: Wikipedia)
RADAR (Radio Detection and Ranging) sensors work similarly to LiDARs. Instead of light, they send out radio waves to derive information about the environment. IMU stands for Inertial Measurement Unit and is used to record the physical movement (angular speed, velocity, reference position, and orientation) of the car. GPS stands for Global Positioning System and is used to geolocate the physical location of the robot.
Making sense of Images
Computer Vision is the field of Computer Science that deals with how computers can be made to gain a high-level understanding from digital images and videos. It tries to automate the tasks that the human visual system can do.
In recent years, Computer Vision has taken great leaps and development. These recent breakthroughs are powered by innovations in Deep Learning technology (both hardware and software). Deep Learning is a field of Machine Learning that makes use of Artificial Neural Networks, a biologically inspired mathematical model of the human brain, to learn patterns in data by going through different examples. The high availability of data (more examples) and powerful computing resources (GPUs) have allowed all the innovations that we see today.
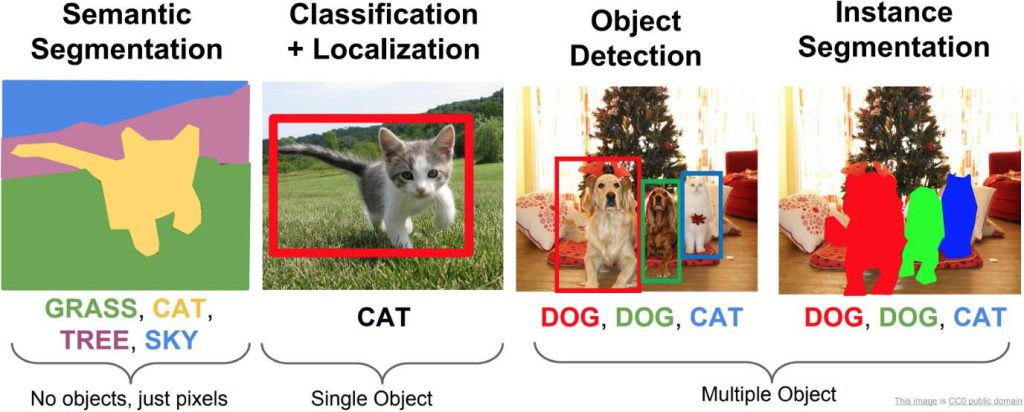
The most common tasks that Computer Vision can accomplish are to recognize (Object Classification), detect (Object Detection), and segment (Instance Segmentation) as can be seen in the image above. Apart from these mainstream tasks, Computer Vision is also a major contributor to Spatial Intelligence. Spatial Intelligence refers to the intelligence that enables us to successfully perceive and derive insights from visual data. In other words, it is the ability to reason about space. To build truly intelligent robots that can perform real-world tasks like navigation, path planning, and object manipulation, spatial intelligence is the first step to achieving all these.
3D Object Detection
There have been numerous state-of-the-art developments for the 2D Object Detection task. Some recent advances include YOLOv5, FasterRCNN, and SSD networks. Their performance on the 2D Object Detection task is remarkable and even surpasses humans in some cases. But, to develop spatial intelligence, we require these networks to work in 3D. By extending the prediction to 3D, one can capture an object’s size, shape, position, and orientation in the real world.
Detecting 3D bounding boxes from a single image is a difficult task. A single image of a scene very well contains a lot of visual information but misses a key component, depth. Humans exhibit what is called stereoscopic vision. We use the images captured by both of our eyes, to retrieve the depth information of the scene. Hence, to compensate for the missing depth, computer systems make use of other depth-sensing technology like RGBD camera images and point cloud data captured from LiDARs. However, research has also been focused on deriving depth information from multiple or even a single RGB image
VoxelNet, PointNet, and Point Pillars are some of the algorithms that make use of solely Point Cloud data to do 3D Object Detection. Frustum Point Net and Multi-View 3D are some of the techniques that make use of images along with point cloud data. Finally, Single Shot 3D and Real-Time Monocular 3D are some techniques that use multiple and single images respectively. The image on the right shows a technique called SFA3D, which uses only LiDAR data

Bird’s Eye View
Autonomous Driving and Navigation require an accurate representation of the environment around the robot car. The environment includes static elements such as the road layout and the lane structures as well as dynamic elements such as pedestrians, cars, and other road users. To perform Path Planning and Navigation, the autonomous car is required to accurately know its surroundings (space). This information is best available in the form of a top-down view or bird’s eye view.
Measurements from various sensors like LiDARs and RADARs are required to be fused to lift the 2D perspective to 3D space Bird’s Eye View. However, just like 3D Object Detection, there do exist certain techniques that make use of only surrounding cameras to generate the BEV. There also exist certain challenges to accomplish this task. One challenge is the knowledge of the camera parameters and knowledge of the road surface and its height. Another challenge is the data collection itself, as to utilize Deep Learning techniques, corresponding data between a front view and a bird’s eye view is required, which can be captured using Drones and other simulation-based techniques. One interesting way to collect the data for the same is from GTA V, by toggling between frontal and bird’s eye view at each game time step. The image above illustrates the game (Credit: Surround Vehicles Awareness Github).
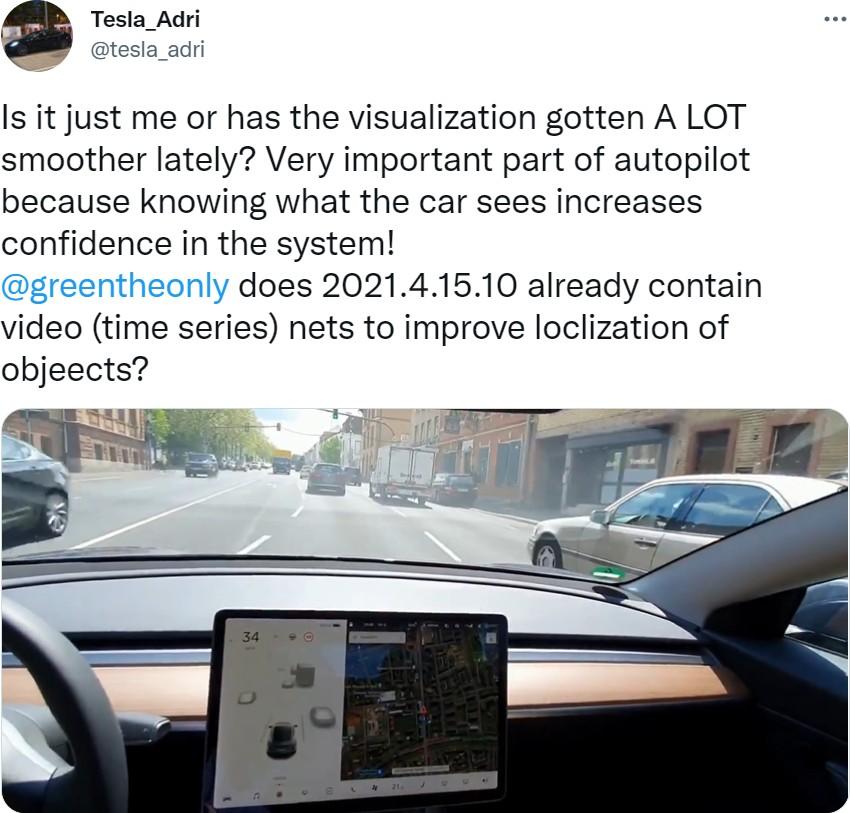
Some of the recent works exploring this problem are: View Parsing Network makes use of synthetic data generated from the CARLA self-driving car simulator and UNetXST network that uses synthetic data generated from VTD (Virtual Test Drive) simulation environment. Apart from using synthetic datasets, multi-sensor datasets like Lyft, Nuscenes also make it possible to do the same task. One interesting approach from Nvidia, Split Splat Shoot makes use of the Lyft and Nuscenes dataset to generate Bird’s Eye View scenes. The image on the right shows a Visualization of the Driving Scenario, the surrounding cars, pedestrians, and traffic lights as can be seen in a Tesla car (Credits: Tweet by Tesla_Adri)
Visual SLAM
SLAM stands for Simultaneous Localization and Mapping. SLAM is a method used by autonomous agents to build a map of an unknown environment and localize itself on the map as well. It is the technology that powers the intelligence in current robots, like Vacuum Cleaner.
Vacuum Cleaners make use of this technology to determine which areas require cleaning, how much to move towards them, and which areas the robot has already visited. Making use of images and video for the SLAM algorithm is what constitutes Visual SLAM.
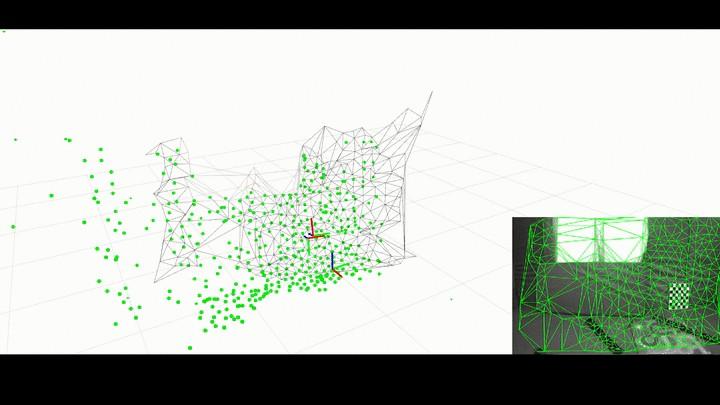
The SLAM process consists of several different steps. The goal of the complete process is to use the information collected from the environment (images in the case of Visual SLAM) to update the position of the robot. The features extracted from the images are called landmarks. An Extended Kalman Filter (EKF) is the heart of the SLAM process. When the position of the robot changes, new landmarks are extracted from the robot environment. The robot then tries to associate these new landmarks to the landmarks it has previously observed. EKF keeps track of position while the robot moves and observes its environment. The image above demonstrates the working of a SLAM algorithm Kimera-VIO (Credits: Kimera VIO Github).
Visual SLAM algorithms are classified into two categories. Sparse methods match feature points extracted from images, like PTAM and ORB-SLAM. Dense methods use the overall brightness and pixel intensity values, like DSO and SVO.
Spatial AI
Spatial AI and 3D Intelligence are the way to building the next generation of smart robots that truly interact with their environments. The Computer Vision research applied to robots will progressively converge to a general real-time geometric and semantic Spatial Intelligence. All this intelligence stems from the visual information that the robot receives from camera images.
However, there are still avenues of research required to achieve this and deal with all the relevant issues. And, after dealing with all these issues, we could truly harness the potential of image data.
References
- Why Tesla won’t use LiDAR? Medium Article by German Sharabok
- How Self-driving Cars Work: Sensor Systems blog by Udacity
- Camera Wikipedia
- Computer Vision Wikipedia
- Everything You Ever Wanted To Know About Computer Vision Medium
- What is Spatial Intelligence? Blog
- Objectron Media Pipe
- Monocular Bird’s Eye View Segmentation for Autonomous Driving Medium
- What is SLAM? MathWorks Blog
- SLAM for Dummies
- From SLAM to Spatial AI YouTube